Article
Que prendre en compte pour la construction d’un Data Lake ?
Que ferions-nous dans un monde sans Data ? Avec l’arrivée du Big Data et la transition numérique toujours plus importante des entreprises, un grand volume de données doit être assimilé, stocké, fiabilisé et surtout sécurisé.
Nous avions déjà abordé le sujet du Master Data Management lors d’un webinar, focalisons notre analyse sur les caractéristiques techniques d’un Data Lake.
Commençons par une définition. Un Data Lake est un élément fondamental dans une architecture orientée Data mais surtout dans la gouvernance de vos données de référence. Ce n’est pas uniquement un espace de stockage de données brutes, c’est aussi la source pour le traitement de ces données par des applications tierces.
D’ailleurs, nous verrons qu’il n’y a pas un, mais des Data Lakes, puisqu’il convient d’adapter sa mise en œuvre à votre usage réel de la donnée.
Un projet Data n’a de sens que lorsque les données sont valorisées et surtout utilisées !
Trop souvent, on construit d’abord un Data Lake et ensuite, on s’intéresse aux cas d’usage en se disant que le Data Lake permettra de tous les couvrir.
Les caractéristiques d’un Data Lake
Un Data Lake associe souvent plusieurs zones de stockage pour répondre à des problématiques différentes. Habituellement, on retrouve donc tout ou partie des zones suivantes :
- Raw Zone : zone de stockage des données brutes.
- Trusted Zone : donnée validée et formatée selon les règles de l’entreprise (format, règles métier, reconstruction des objets métier).
- Sandbox : zone bac à sable (souvent pour de l’analytique).
- Refined Zone : zone spécifique à un besoin métier.
Il parait évident que la mise en œuvre d’une telle architecture va demander du temps et des efforts conséquents. C’est pourquoi, il est tentant dans un premier temps de limiter à une unique zone l’implémentation du Data Lake.
Vous pouvez opter pour une architecture plus simple, un entrepôt unique avec :
- Une base SQL
- Une base NoSQL
NB : Volontairement, nous ne citons pas les systèmes de fichiers (ou les systèmes de stockage objet ou blocs) car ils répondent difficilement aux exigences des besoins temps réels, vous obligeant à revoir très tôt votre architecture.
Le fait d’avoir un seul système va simplifier :
- La gestion des droits d’accès,
- Le monitoring,
- Le déploiement continu,
- L’Infrastructure as Code (IaC).
Surtout, cela va vous permettre une mise en œuvre rapide afin d’affiner vos besoins fonctionnels et techniques.
Quelles questions se poser pour mettre en place un Data Lake ?

Les différentes phases de mise en œuvre d’un Data Lake
La phase de découverte est la première étape obligatoire d’un projet de construction d’un Data Lake.
C’est le moment où l’on va se poser des questions importantes : Où stocker les données ? Selon quel format ? Selon quelle hiérarchie ? Quelles applications doivent y accéder ?
Il est cependant rare d’avoir toutes les réponses nécessaires à ce moment-là et d’autres questions purement techniques ne doivent pas être négligées.
Et pourtant, elles restent souvent sans réponse au démarrage d’un projet et c’est normal :
- Combien d’utilisateurs au lancement et leur évolution dans le temps ?
- Combien d’accès par seconde et en pic sur chacun des services de la plateforme ?
- Quelle est la volumétrie attendue ?
- Quel est le SLA ?
Quand on prend en compte toutes les contraintes, tous les besoins beaucoup trop tôt dans la vie du projet, on arrive à une architecture de compromis qui va probablement être surdimensionnée, mal adaptée (car correspondant à trop de cas d’usage différents) et surtout difficile à maintenir.
Certaines phases sont complexes à traiter par leur étendue et par leur impact sur l’organisation de l’entreprise, comme la gouvernance par exemple. Il est donc difficile d’imaginer ne pas avoir à revenir sur un choix d’architecture par la suite.
La gouvernance, la sécurité sont des chantiers au long court et ce sont des domaines où l’on a tendance à surestimer les besoins réels et à se couvrir inutilement. On cherche donc à construire l’architecture idéale.
L’architecture idéale coûte cher, est longue à implémenter et est plus difficile à maintenir. De plus, les besoins changent et ne peuvent être anticipés.
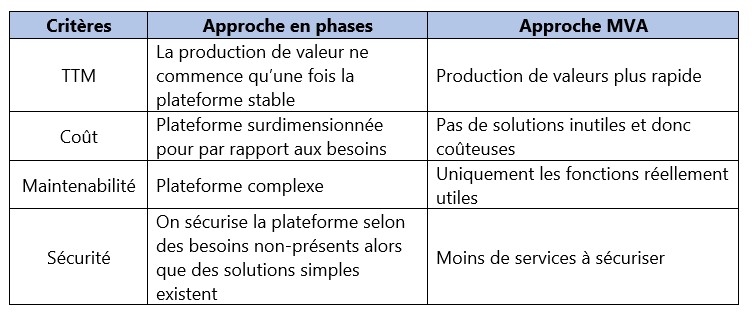
Cela ne veut pas dire qu’un sujet ne sera pas être traité, mais que son implémentation peut être simplifiée dans l’objectif d’un Time To Market (TTM) court. Cela permettra de mieux cerner les besoins réels et d’éviter d’imposer la règle la plus contraignante à toute la plateforme.
Et si on parlait agilité ?
L’agilité, c’est une construction par itération d’un produit. Il est donc pertinent d’appliquer ce principe à l’architecture et donc de mettre en place la notion de Minimum Viable Architecture (MVA).
Chaque itération produit un MVP (Minimum Viable Product) s’appuyant sur une architecture nécessaire et suffisante. On a trop souvent tendance à sur-architecturer et ne penser qu’au produit final et pas au produit intermédiaire.
L’architecture parfaite n’existe pas et surtout elle n’est souvent pas pour vous (non pas parce que vous ne le méritez pas mais, cela ne correspond pas à vos besoins).
Ce n’est pas valable uniquement pour les projets Data mais si une architecture n’évolue pas, ne subit de réajustement dans la phase de construction d’une solution, c’est que vous avez sur-architecturer ou mal découpé vos sprints.
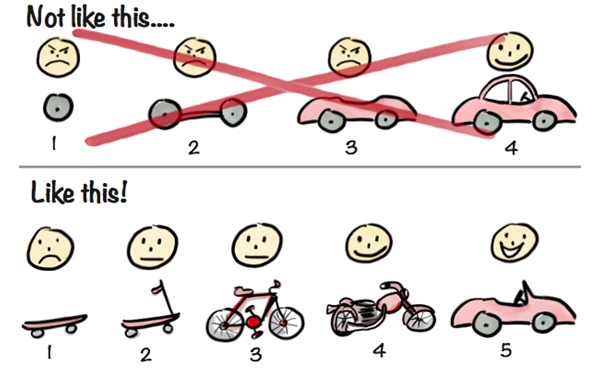
Source : https://blog.crisp.se/2016/01/25/henrikkniberg/making-sense-of-mvp
On comprend mieux avec l’image célèbre ci-dessus :
- Les décisions d’architecture sont réversibles.
- L’architecture est testable dès la première itération.
- Le service est fourni dès la première itération.
Une fois les besoins mieux cernés alors on pourra progressivement étoffer cette architecture mais toujours de manière itérative et avec à l’esprit que si cette évolution n’apporte rien en termes de fonctionnalités ou de confort, il ne faut pas hésiter à faire machine arrière.
Un découplage entre services et implémentation et de manière générale entre métier et technique est la clé pour une architecture évolutive.
L’évolution de la volumétrie, des typologies d’accès, des profils vont peut-être vous contraindre à revoir votre copie quand ce n’est pas abandonner certaines solutions qui jusque-là répondaient parfaitement au cahier des charges. C’est le prix à payer pour établir la bonne architecture adaptée à votre cas.
Évidemment à terme, l’architecture va se stabiliser en même temps que la couverture des besoins va augmenter.
N’oubliez jamais qu’il faut produire de la valeur le plus rapidement possible.
Enfin un dernier point sur la validation des plateformes et donc de la MVA.
C’est évidemment très important mais trop souvent il y a méprise sur le rôle de cette phase : le but n’est pas de tester une solution, mais son utilisation dans votre contexte.
En conclusion
La technique n'étant qu'un moyen et non une finalité, apporter de la valeur doit être au cœur de tous les projets Data et doit être réalisée le plus rapidement possible dans le projet.
Le Data Lake n’est plus ou n’a jamais été un entrepôt unique mais plutôt une succession d’espaces adaptés à un besoin (fréquence et type d’accès, performances, …)
Un Data Lake stocke des données plus ou moins structurées, provenant de systèmes hétérogènes, qu’il doit exposer pour des besoins qui possèdent des caractéristiques fondamentalement différentes :
- Consistance de la donnée d’un point de vue métier,
- Accès en temps réel,
- Volumétrie importante.
Cela correspond à des profils d’utilisateurs différents :
- Métier
- Data Scientist
- APIs accédées par des applications
Dans le temps de nouveaux besoins peuvent apparaître, et même les besoins initiaux sont souvent changeants.
Il n’y a pas de miracle, le Data Lake générique n’existe pas !
Le chemin vers une entreprise centrée sur la donnée ne peut être linéaire si on veut éviter l’effet tunnel. Il est fait de bonds technologiques plus ou moins grands tout en assurant une évolution constante des services proposés pour que son utilisation au sein de l’entreprise soit progressive.
Enfin, il existe une tendance actuelle qui facilite cette approche, car elle donne le droit à l’erreur architecturale (pas d’engagement en termes de licence, de matériel ou même d’administration), il s’agit évidemment du cloud et plus particulièrement de la mouvance Serverless.
Liens de ressources utiles :
- Blog : https://www.softwareyoga.com/minimum-viable-architecture/
- Livre : Architecting Data Lakes
- Livre blanc : https://www.zaloni.com/resources/briefs-papers/data-lake-maturity-model/
Source d'illustration :