Article
Le Graal de la Data Science
La Data Science, on en a tous entendu parler ! Mais de quoi parle-t-on exactement ? Comment suivre la tendance ? Nous vous apportons des premiers éléments de réponses !
La définition simple d’une discipline complexe
Pour faire simple, nous pouvons dire que la Data Science est l’art de faire parler les données en développant des méthodes et algorithmes de plus en plus intelligents pouvant automatiser l’extraction des infos pertinentes à destination des décideurs et sur des volumes d’informations toujours plus gros et variés.
L’algorithme doit prendre en considération le contexte Business, les données historiques (plus gros est le volume, mieux c’est) et utiliser des méthodes statistiques basées sur les probabilités, notamment pour faire ressortir l’info Business clé (KPIs) et aussi pouvoir « prédire » l’évolution de ces KPIs. La grande force de ces nouveaux algorithmes est que le modèle s’affine avec le temps et la pertinence de ce dernier se renforce.
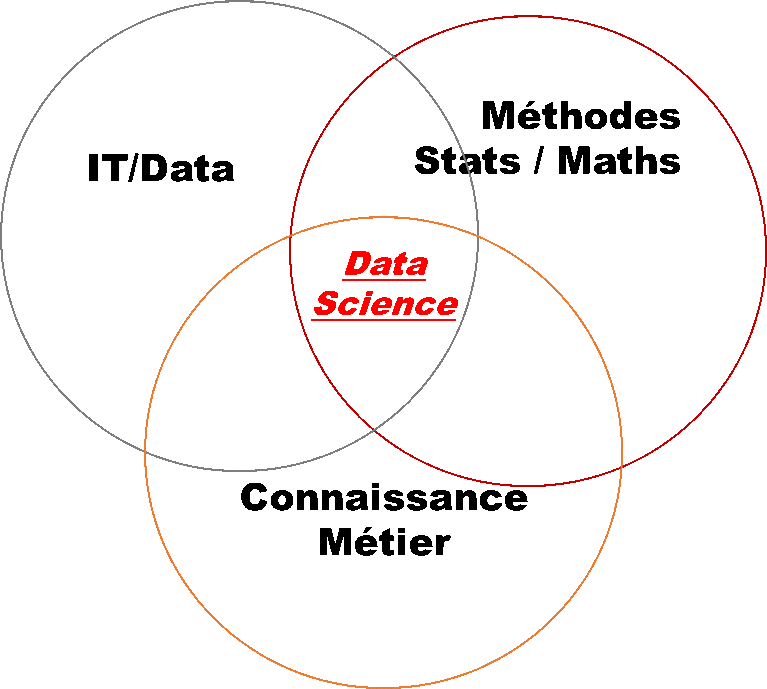
La complexité réside dans le fait qu’elle mixe des aptitudes :
- Techniques (notamment sur la Data et le code informatique)
- Fonctionnelles (connaissance des enjeux métier et du secteur d’activité)
- Mathématiques (Méthodes statistiques complexes)
Dans le modèle de nos entreprises actuelles, il est difficile de trouver toutes ces compétences réunies dans un seul service, et pire dans une seule personne !
Allez Hop on se lance ! … Mais comment ?
Ce n’est vraiment pas simple de se lancer lorsque l’on n’a jamais mené ce genre de projet. Tout d’abord il faut savoir que la Data Science n’est pas vraiment un projet, c’est une philosophie, une démarche d’entreprise : il s’agit de faire de la fouille de données, de comprendre un fait, cerner un problème, mettre le doigt sur les facteurs d’un échec ou de la contre-performance d’un produit ou d’une campagne. Même si chaque cas est différent, voici les différentes étapes pour mettre en place la démarche (on ne parle plus de projet !) :
-
Etape 1 : Construire une équipe
Les initiatives fleurissent dans le secteur privé. Cela passe généralement par la création d’un pôle Datalab transverse à toute l’entreprise et regroupant les fameuses compétences évoquées ci-dessus : mathématiques et statistiques, fonctionnelles et IT. Constituée au départ d’une petite dizaine de personnes, elle a pour rôle de tester et choisir les outils du marché, répondre aux demandes du marché par des analyses et participer au déploiement. N’hésitez pas à vous faire accompagner par des experts dans la création ou l’optimisation de votre propre laboratoire.
-
Etape 2 : Comprendre le besoin métier
Les besoins métier sont très souvent des besoins de fouilles de données pour comprendre un problème et trouver des solutions. La démarche est la création d’un brief par le métier qui est ensuite pris en compte par le Datalab. Les analyses sont en général assez courtes.
-
Etape 3 : Rassembler les données
Une fois que l’on connait le besoin, le Data Scientist est en mesure de lister les données dont il a besoin. Cela passe généralement par la constitution d’un Datalake ou Datahub, regroupant les données brutes de toutes l’entreprise (à terme). Les architectures techniques choisies (Big Data) permettent au Data Scientist de traiter ce volume important et non structuré de données dans ses algorithmes. ASI est en mesure de vous accompagner dans la mise en place des Hubs de données et d’architectures Big Data.
-
Etape 4 : Modéliser
La modélisation consiste à l’élaboration des algorithmes et des modèles statistiques. C’est cette étape qui est réellement de la Data Science : on retraite les données, choisit nos algorithmes. Des outils dédiés peuvent vous aider à modéliser et permettent de mettre la Data Science à la portée de plus de profils. Ces solutions que l’on appelle « Plateformes de Data Science » sont de plus en plus nombreuses. Il est parfois difficile de choisir la mieux adaptée, et il peut être intéressant de mener un projet de « choix d’outil ».
-
Etape 5 : Tester notre modèle
Tester le modèle est primordial ! Il permet de vérifier que le modèle imaginé peut s’appliquer dans la vraie vie. Pour cela on le fait tourner sur une période passée et on compare la prédiction avec le réel. Par exemple, si nous sommes en 2017, nous faisons tourner notre modèle avec en entrée les données 2013 à 2015 pour prédire 2016. Nous comparons ensuite les résultats du modèle (prédictions 2016) avec le réel 2016 que nous avons sous la main. Si les résultats sont proches alors nous pouvons valider notre modèle. Sinon on travaille en mode itératif en repassant à l’étape 4, et ce jusque la validation d’un modèle.
-
Etape 6 : Industrialiser
Industrialiser consiste à intégrer le modèle développé dans les processus de l’entreprise pour fluidifier des tâches opérationnelles, optimiser les traitements, faciliter les prises de décisions. Les moyens d’industrialiser sont nombreux. En général, le Datalab collabore avec la DSI pour mettre en place de nouveaux tableaux de Bord ou ajouter des KPIs dédiés. Ces 6 étapes sont valables pour le premier cas d’usage. Ensuite, les analyses suivantes pourront commencer à l’étape 3 voire la 4 si nous avons déjà à disposition les données !
La valeur créée par la mise en place d’une démarche de Data Science est énorme. L’apport par rapport à la Business Intelligence classique est la fiabilité des analyses et des projections grâce à l’utilisation de méthodes statistiques complexes qui ont fait leurs preuves. De plus, le fait de travailler sur des problématiques concrètes et en mode agile permet d’avoir des résultats probants dès les premières expériences et donc un ROI relativement court.