Article
Data Preparation : Cas pratique avec Trifacta Wrangler
Pour continuer à se familiariser avec les outils de Data Preparation présentés dans l'article « Qu’est-ce que la Data Preparation et à quoi sert-elle ? », et maintenant que nous avons découvert le fonctionnement de Talend Data Preparation, nous allons aujourd’hui mettre en pratique un cas concret avec Trifacta Wrangler. Dans cet exemple, les données ne sont pas très propres. Nous allons tenter de corriger les valeurs manquantes, éliminer les valeurs aberrantes, enrichir le jeu avec une autre source, et construire une adresse email à partir de colonnes existantes.
Etape 1 : Chargement des données
Lancer Trifacta Wrangler :

Dans la barre horizontale haute, nous remarquons les trois Eléments essentiels, FLOWS (Flux), DATASETS (Sources), RESULTS (Résultats) ainsi que l’interface de chaque élément.
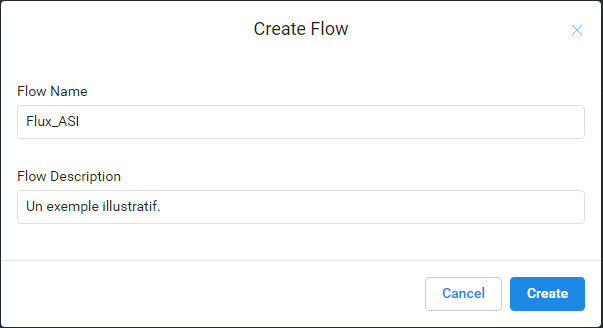
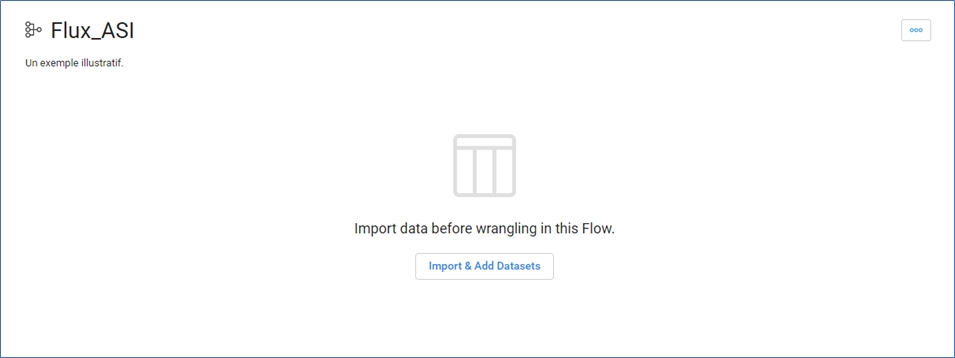
Créer un nouveau Flux de travail et le nommer Flux_ASI :
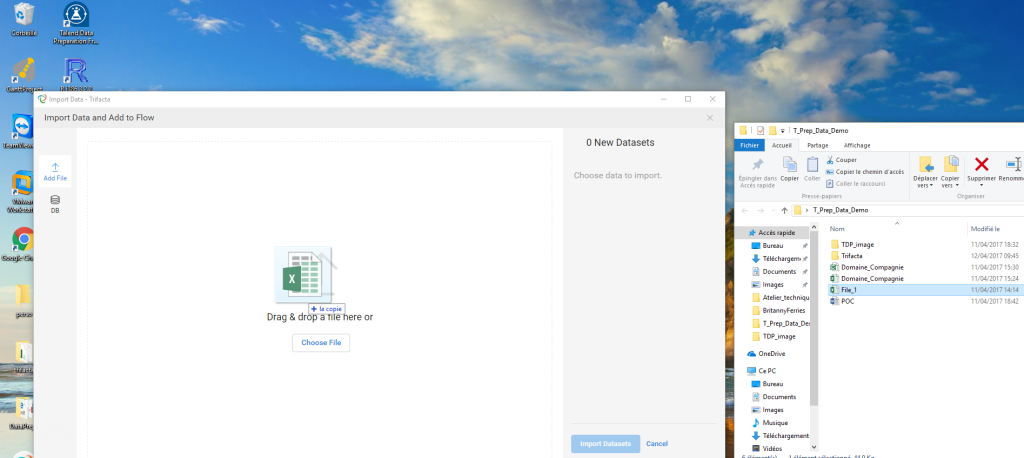
Ajouter les DATASETS (sources), soit par drag & drop (glisser-déposer), ou en cliquant sur Choose File :
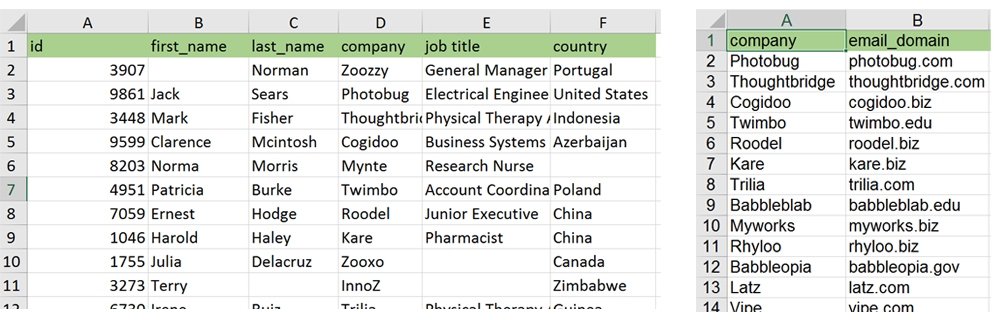
le premier (SALARIES) servira de flux primaire
- le second (DOMAINE_COMPAGNIE) contient 2 colonnes (nom et mail de l’entreprise). La jointure avec le premier se fera sur le champ ‘company’.
Etape 2 : Découverte des données
Une fois le DATASET ajouté, Trifacta propose un premier tableau de bord :
Il permet de voir la constitution du flux (dans le volet à droite, nous pouvons voir un premier aperçu des données ainsi que les premières étapes de la recette).
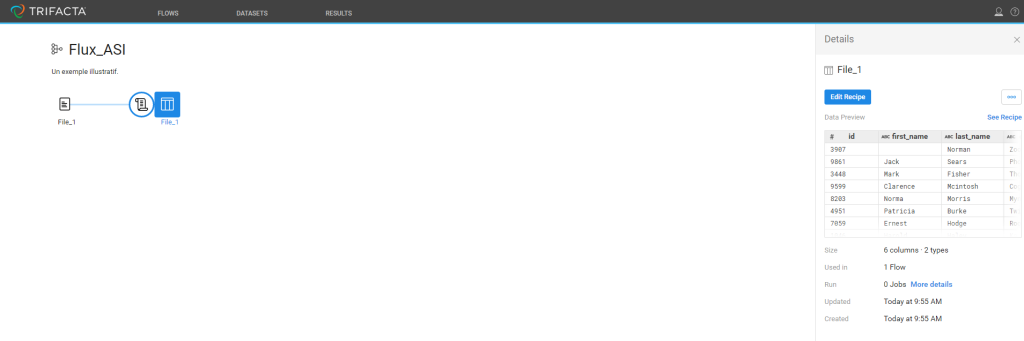
- Dans le volet à droite, cliquer sur ‘Edit Recipe’ pour aller à l’interface principale

L’interface principale propose un tableur pour visualiser les données :
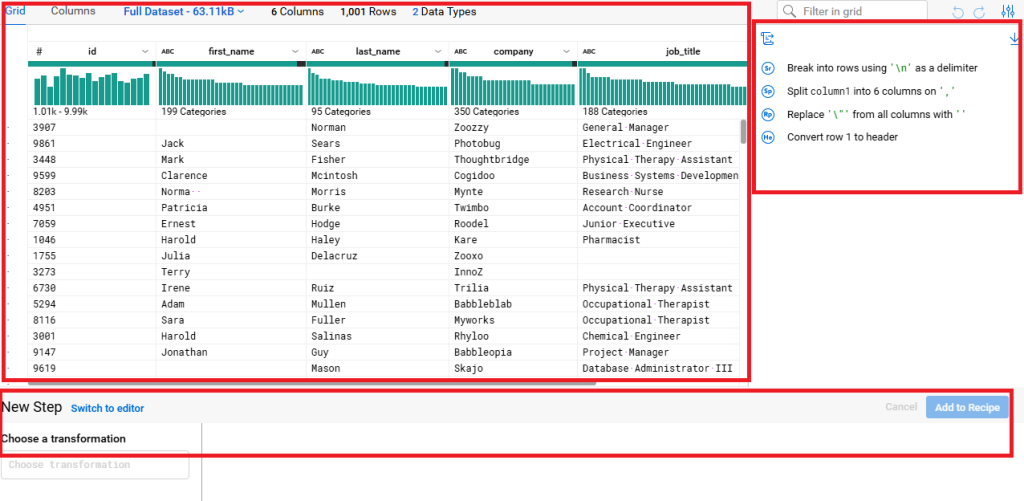
A droite, le volet permet de voir la recette. En bas, un builder contient l’ensemble des fonctions de transformations. Pour chaque colonne, une barre de Data Quality est présente, avec trois couleurs : verte (valeurs valides), rouge (valeurs invalides) et noire (valeurs nulles). En cliquant sur chaque tranche, il est possible d’accéder aux actions pouvant être appliquées à cette masse de données. Dans notre cas, nous allons accéder à la première colonne, et voir les détails de la colonne.
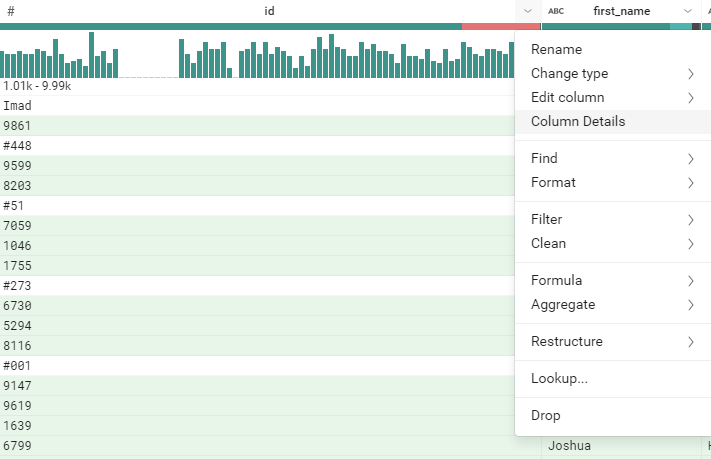
En cliquant sur ‘Column Details’, nous aurons un tableau de bord de Data Profiling de cette colonne.
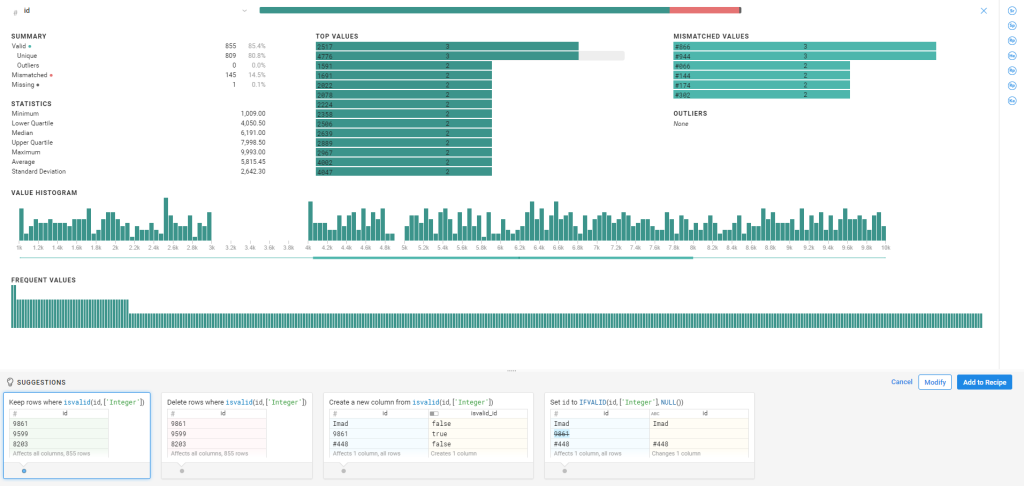
Etape 3 : Nettoyage
Nous allons éliminer les valeurs aberrantes (invalides) et les valeurs nulles :
Nous allons commencer par les valeurs nulles
- Cliquer sur la partie noire de la barre de Data Quality, Trifacta suggère un ensemble d’actions
- Choisir l’action Delete rows where isMissing ([id])
- Cliquer sur ‘Add to Recipe’. Il est également possible de cliquer sur ‘Modify’ pour avoir une transformation plus adaptée. La force de Trifacta est de pouvoir ajouter des expressions régulières et combiner plusieurs fonctions.
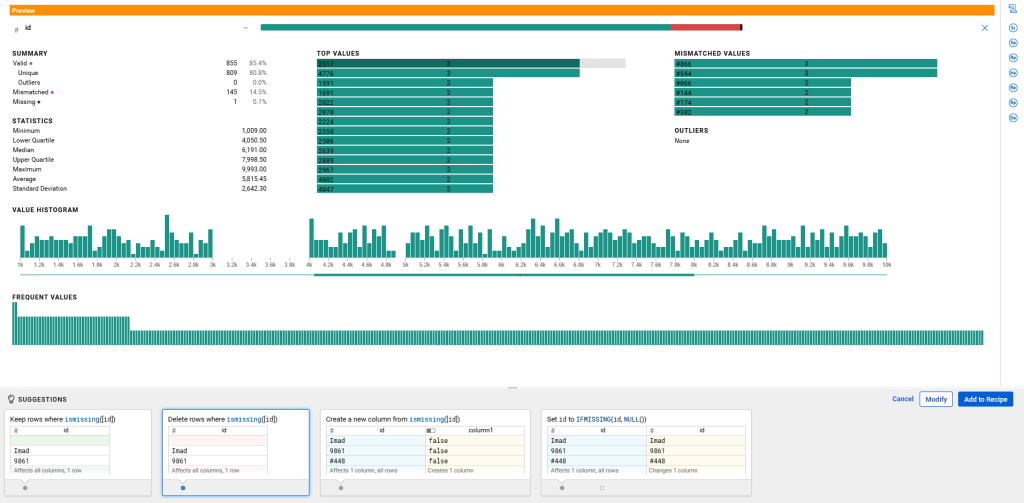
Pour les valeurs aberrantes :
- Cliquer sur la partie rouge de la barre de Data Quality
- Appliquer l’action Delete rows where ismismatched([id], [‘Integer’])
- Cliquer sur ‘Add to Recipe’
- Répéter ces actions pour toutes les colonnes du jeu de données.
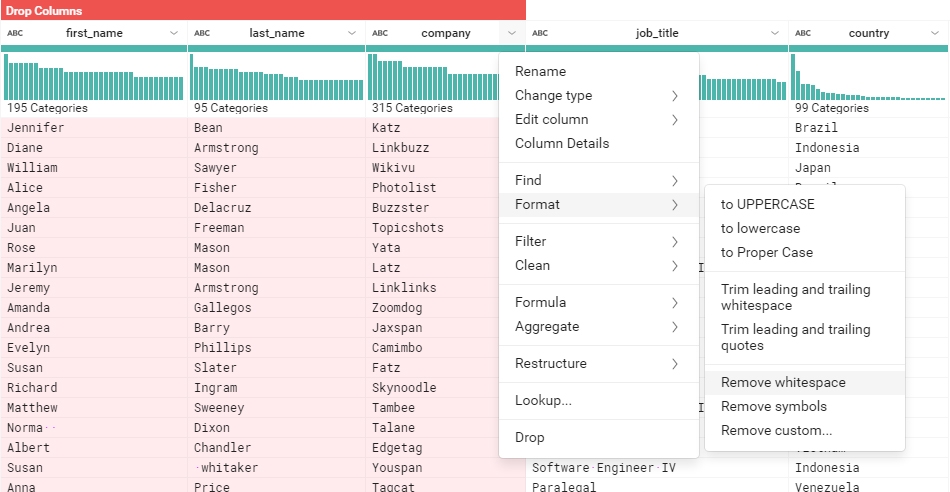
Nous allons maintenant supprimer les espaces de toutes les colonnes :
- Sélectionner les colonnes concernées avec Ctrl+Clic
- Cherche la fonction Remove whitespaces() qui se trouve dans le menu ‘Format’, et l’appliquer pour toutes les colonnes
Nous allons créer deux nouvelles colonnes, qui contiendront respectivement le firstname et lastname de la personne afin de les mettre en minuscule :
Nous allons les appeler respectivement Email_Firstname et Email_Lastname :
- Cliquer sur le menu déroulant de la colonne
- Dans Format, chercher la fonction to lowercase ()
- Dans le builder des options de paramétrages, choisir la formule, et renommer la nouvelle colonne Email_First_Name.
- Répéter cette action pour la colonne last_name
Etape 4 : Enrichissement
Nom de domaine de l'entreprise
Nous allons, dans cette étape, enrichir le jeu de données avec un nouveau flux, afin d’extraire le nom du domaine de l’entreprise pour chaque salarié :
- Cliquer sur le menu déroulant de la colonne company
- Choisit Lookup, une nouvelle fenêtre apparait pour choisir le DATASET concerner par la jointure
- Choisir le DATASET ‘Domaine_Compagnie’
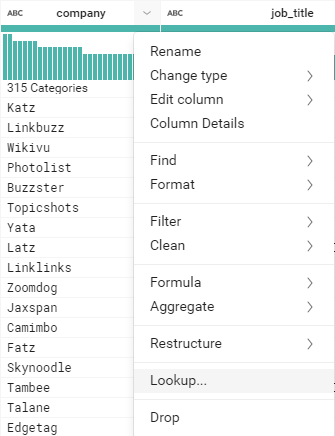
L’étape 2 du Lookup consiste à choisir l’attribut de jointure dans le DATASET secondaire :
- Choisir ‘company’
- Exécuter le Lookup
Une fois le fichier chargé, nous allons construire la colonne ‘EMAIL’.
Comme Trifacta propose de faire nos propres formules, nous allons sélectionner les trois colonnes concernées, puis nous allons appliquer la fonction Merge() sur les trois colonnes avec un tiret entre le firstname et lastname et un @ entre la colonne résultante et le domaine_compagny. La figure suivante montre comment nous avons pu combiner plusieurs fonctions pour construire une formule. Dans notre exemple, nous avons fait plusieurs étapes en une seule grâce à la formule suivante : MERGE ([MERGE([Lower(first_name),Lower(last_name)], ‘-’),email_domain], ’@’).
![]()
Etape 5 : Validation et Publication
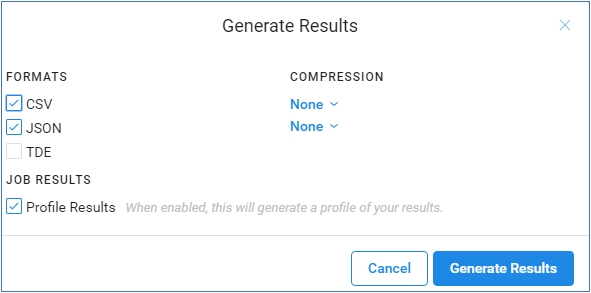
En haut à droite, Trifacta permet de générer le résultat des transformations.
Avec la version gratuite, il est possible d’exporter les résultats sous trois formats : CSV, JSON et TDE.
Le résultat sera publié dans le logiciel lui-même. Pour le voir, cliquer dessus afin d’avoir un tableau de bord résumant le résultat obtenu.

En conclusion, l’arrivée de la Big Data engendre forcément une explosion d’outils qui permettent aux entreprises de tirer profit de leurs données. Les éditeurs de ces solutions essayent de fournir des outils simples permettant à l’utilisateur sans compétences informatiques de se les approprier facilement. Le domaine de la data preparation suit cette logique de vulgarisation (démocratisation). Cependant les outils qui permettent de le faire sont encore jeunes. Les solutions ne sont pas complètes ; plusieurs défis attendent les éditeurs. La data preparation pourra permettre aux entreprises de passer plus de temps dans l’analyse des données, permettant d’accélérer les projets et d’avoir de meilleurs résultats.